

 题目内容
(请给出正确答案)
题目内容
(请给出正确答案)
[判断题]
视图在数据库中以存储的数据值集形式存在。()
 答案
答案
查看答案
 请输入或粘贴题目内容
搜题
请输入或粘贴题目内容
搜题
 拍照、语音搜题,请扫码进入小程序
题目内容
(请给出正确答案)
答案
拍照、语音搜题,请扫码进入小程序
题目内容
(请给出正确答案)
答案
 更多“视图在数据库中以存储的数据值集形式存在。()”相关的问题
更多“视图在数据库中以存储的数据值集形式存在。()”相关的问题
第2题
A.首先查询出视图中所包含的数据,再对进行查询
B.直接对数据库存储的视图数据进行查询
C.将对视图的查询转换为对相关基本表的查询
D.不能对基本表和视图进行连表操作
第4题
A.Hadoop
B.Impala
C.Spark
D.BigTable
第6题
关于混悬剂特点的叙述中哪一项是不正确的
A、混悬剂中的药物以固体微粒的形式存在,可以提高药物的稳定性
B、混悬剂中的难溶性药物的溶解性低,从而导致药物的溶出速度低,达到长效作用
C、F值在0~1之间,F值愈小混悬剂愈稳定
D、β值愈大,絮凝效果愈好,混悬剂的稳定性愈高
E、混悬剂相比于固体制剂更加便于服用
第9题
利用DISCRIM.RAW中的数据回答本题。(也可参见第3章计算机练习C8。)
(i)利用OLS估计模型
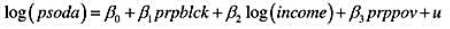
以常用形式报告结果。在5%的显著性水平上,相对一个双侧备择假设,β统计显著异于零吗?在1%的显著性水平上呢?
(ii)log(income)和prppov的相关系数是多少?每个变量都是统计显著的吗?报告双侧P值。
(iii)在第(i)部分的回归中增加变量log(hseval)。解释其系数并报告 的双侧p值。
的双侧p值。
(iv)在第(ii)部分的回归中,log(income)和prppov的个别统计显著性有何变化?这些变量联合显著吗?(计算一个p值。)你如何解释你的答案?
(v)给定前面的回归结果,在确定一个地区的种族构成是否影响当地快餐价格时,你会报告哪一个结果才最为可靠?
第10题
试设计如图3-2中显示的数据库模式Library,用来记录书籍、借书人和书籍借出的情况,参照完整性在图中用有向弧来表示。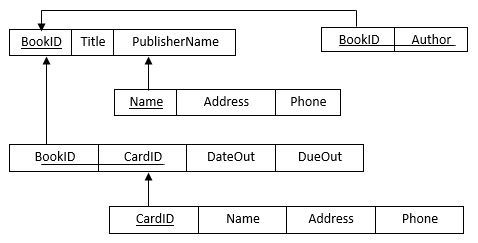 请用SQL语言建立图中的关系模式,并完成下列操作: ⑴ 查询“高等教育出版社”出版的所有图书名称和编号。 ⑵ 查询所有作者是“郭雨辰”的图书的编号和名称。 ⑶ 查询“王丽”借过的所有图书的名称。 ⑷ 查询“李明”在2018年上半年期间借过的图书名称。 ⑸ 建立视图,显示2017年期间没有被人借过的图书编号和名称。 ⑹ 建立超期未归还书籍的视图,显示图书编号和名称,以及借书人姓名和电话。 ⑺ 建立热门书籍的视图,显示2017年期间借出次数最多的10本图书名称。 ⑻ 增加新书《大数据》,书号为“TP319-201”,该书由“广西师范大学出版社”出版,作者为“涂子沛”。 ⑼ 将“高等教育出版社”的电话改为“010-64054588”。 ⑽ 删除书号为“D001701”的书籍信息。
请用SQL语言建立图中的关系模式,并完成下列操作: ⑴ 查询“高等教育出版社”出版的所有图书名称和编号。 ⑵ 查询所有作者是“郭雨辰”的图书的编号和名称。 ⑶ 查询“王丽”借过的所有图书的名称。 ⑷ 查询“李明”在2018年上半年期间借过的图书名称。 ⑸ 建立视图,显示2017年期间没有被人借过的图书编号和名称。 ⑹ 建立超期未归还书籍的视图,显示图书编号和名称,以及借书人姓名和电话。 ⑺ 建立热门书籍的视图,显示2017年期间借出次数最多的10本图书名称。 ⑻ 增加新书《大数据》,书号为“TP319-201”,该书由“广西师范大学出版社”出版,作者为“涂子沛”。 ⑼ 将“高等教育出版社”的电话改为“010-64054588”。 ⑽ 删除书号为“D001701”的书籍信息。
第11题
对(许多美国工人可用的)401(k)养老金计划的出现是否提高了净储蓄,吸引了大量研究兴趣。数据集401KSUBS.RAW包含了有关净金融资产(nettfa)、家庭收入(ic)、是否有资格参与401(k)计划的二值变量(e401k)和其他几个变量的信息。
(i)样本中有资格参与一个401(k)计划的家庭比例是多少?
(ii)估计一个用收入、年龄和性别解释401(k)资格的线性概率模型。包括收入和年龄的二次项,并以通常形式报告结论。
(iii)你认为401(k)资格独立于收入和年龄吗?性别呢?请解释。
(iv)求第(ii)部分中估计的线性概率模型的拟合值。有小于0或大于1的拟合值吗?
(v)利用第(iv)部分中的拟合值e401k1,定义e401k1在e401k≥0.5时取值1,并在2e401k<0.5时取值0。在9275个家庭中,预计有多少家庭有资格参与401(k)计划?
(vi)对于没有资格参加401(k)的5638个家庭,利用预测值e401k1,预测其中有多大比例没有401(k)?对于有资格参加401(k)的3637个家庭,其中有多大比例的家庭有401(k)?(如果你的计量经济软件具有“制表”命令更好。)
(vii)总正确预测比约为64.9%。给定第(vi)部分的答案,你认为这是模型好坏的一个完备描述吗?
(viii)在线性概率模型中增加一个解释变量pira。其他条件不变,若一个家庭有某人拥有个人退休金账户,一个家庭有资格参与401(k)计划的估计概率会提高多少?在10%的显著性水平上,它统计显著异于0吗?






















