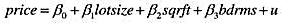题目内容
(请给出正确答案)
题目内容
(请给出正确答案)
[主观题]
在教材第7章7.7节曾介绍利用时域特性的解卷积方法,实际问题中,往往也利用变换域方法计算解卷
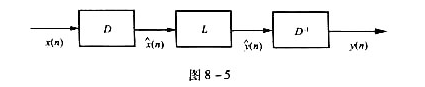
积.本题研究一种称为“同态滤波"的解卷积算法原理.在此,需要用到z变换性质和对数计算.设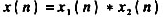 ,若要直接把相互卷积的信号x1(n)与x2(n)分开将遇到困难.但是,对于两个相加的信号往往容易借助某种线性滤波方法使二者分离.图8-5示出用同态滤波解卷积的原理框图,其中各部分作用如下:
,若要直接把相互卷积的信号x1(n)与x2(n)分开将遇到困难.但是,对于两个相加的信号往往容易借助某种线性滤波方法使二者分离.图8-5示出用同态滤波解卷积的原理框图,其中各部分作用如下:
,若要直接把相互卷积的信号x1(n)与x2(n)分开将遇到困难.但是,对于两个相加的信号往往容易借助某种线性滤波方法使二者分离.图8-5示出用同态滤波解卷积的原理框图,其中各部分作用如下:(1)D运算表示将x(n)取z变换、取对数和逆z变换,得到包含x1(n)与x2(n)信息的
相加形式.
(2)L为线性滤波器,容易将两个相加项分离,取出所需信号.
(3)D-1相当于D的逆运算,也即取z变换、指数以及逆z变换,至此,可从x(n)中按需要分离出x1(n)或x2(n)完成解卷积运算.
试写出以上各步运算的表达式.
 答案
答案
查看答案

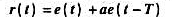
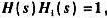 设计一个逆系统,先求它的系统函数Hi(s);
设计一个逆系统,先求它的系统函数Hi(s);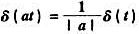 .(利用教材图1-28,当以t为自变量时脉冲底宽为t,而改以at为自变量时底宽变成
.(利用教材图1-28,当以t为自变量时脉冲底宽为t,而改以at为自变量时底宽变成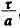 借此关系以及偶函数特性即可求出以上结果.)
借此关系以及偶函数特性即可求出以上结果.)